LLM 隐私及安全相关调研材料
About LLM Security & Privacy
主要问题
- LLM 流程中哪些步骤会涉及隐私泄露,涉及的具体隐私信息是什么?
- 针对相关的隐私安全问题对应的技术?
LLM 数据隐私
News about LLM Safety
-
2023年3月25日,OpenAI发文证实,部分ChatGPT Plus服务订阅用户可能泄露了部分个人隐私和支付信息。
-
2023年10月30日,美国总统签署行政命令为人工智能的安全、保障和道德应用建立了新的基准,保证充分利用人工智能的潜力并降低人工智能的风险。其中,隐私保护是关注的重点之一。
-
2023年11月29日,OpenAI定制聊天机器人GPT正在泄露用户隐私
- the initial instructions the chatbots were given when they were created
- download the files used to customize the chatbots.
LLM全生命周期均存在隐私风险
参考:浅谈大模型数据隐私
不同参与者有各自的敏感资产和隐私保护需求
数据所有者
隐私数据资产(作为模型的训练数据)
隐私问题:
- PII(Personally Identifiable Information)数据要先脱敏,不参与训练
- 不能根据训练得到的模型反推出参与训练的数据 → 成员推断攻击MIA or 训练数据推断攻击
- 避免根据模型给出的辅助信息(输出标签)和某些特征的情况下,恢复敏感特征或完整数据样本 → 重构攻击(Reconstruction Attacks)
模型所有者
模型参数和配置
隐私安全问题:
-
不泄露模型参数 → 模型提取攻击(Model Extraction Attack)
-
因该遵循规范和限制, 不产生冒犯性输出、违反内容监管输出,或隐私数据泄漏的输出 → 模型越狱 (jailbreaking)
- Prompt injection
- 直接指令, 间接指令,Scam Through Plugins(通过插件进行诈骗?)
- 实现:Goal Hijacking(输出有害言论等)& Prompt Leaking(泄露之前的prompt)
- 直接注入攻击,Best Paper Awards @ NeurIPS ML Safety Workshop 2022: Ignore Previous Prompt: Attack Techniques For Language Models
- 实证研究了解越狱攻击所带来的潜在威胁以及现有的越狱防御措施,首个系统性成功对Bard和Bing Chat实施攻击的工作:MasterKey (NDSS’ 24)
- 间接提示注入攻击方式对LLM集成应用的影响,提出新的安全威胁,并强调了对这些威胁的防御的重要性: Not what you’ve signed up for: Compromising Real-World…
- Prompt injection
-
数据中毒:通过插入错误标记的数据修改模型的训练集,诱使它做出错误的预测 → 模型性能下降
-
后门攻击:类似数据中毒,但保留了模型的预期功能
模型服务使用者
prompt 中包含敏感信息
-
服务提供者需要进行安全提示,辅助脱敏;且不降低服务质量(输出结果的时候仍符合预期)
-
大模型提示词隐私保护(Prompt Privacy Protection)
- Hide and Seek(腾讯安全玄武实验室):用户与云端大型模型交互的提示词(Prompts)中可能泄露的个人或企业的隐私敏感信息,在保护敏感信息隐私的同时保证生成输出的可用性(优点:轻量化、端到端,支持匿名信息还原)
-
Meta 开源了 LlamaGuard-7b,实现对用户输入和模型输出内容的双向检查 【2023.12.7发布】
- link: Hugging Face
-
相关产品:主要保证交互阶段的安全可靠 (主要针对prompt数据中存在的PII数据,进行匿名化处理)
- 交互阶段的保护:sanitization, detection of harmful language, prevention of data leakage, and resistance against prompt injection attacks: LLM Guard
- replacing sensitive data:
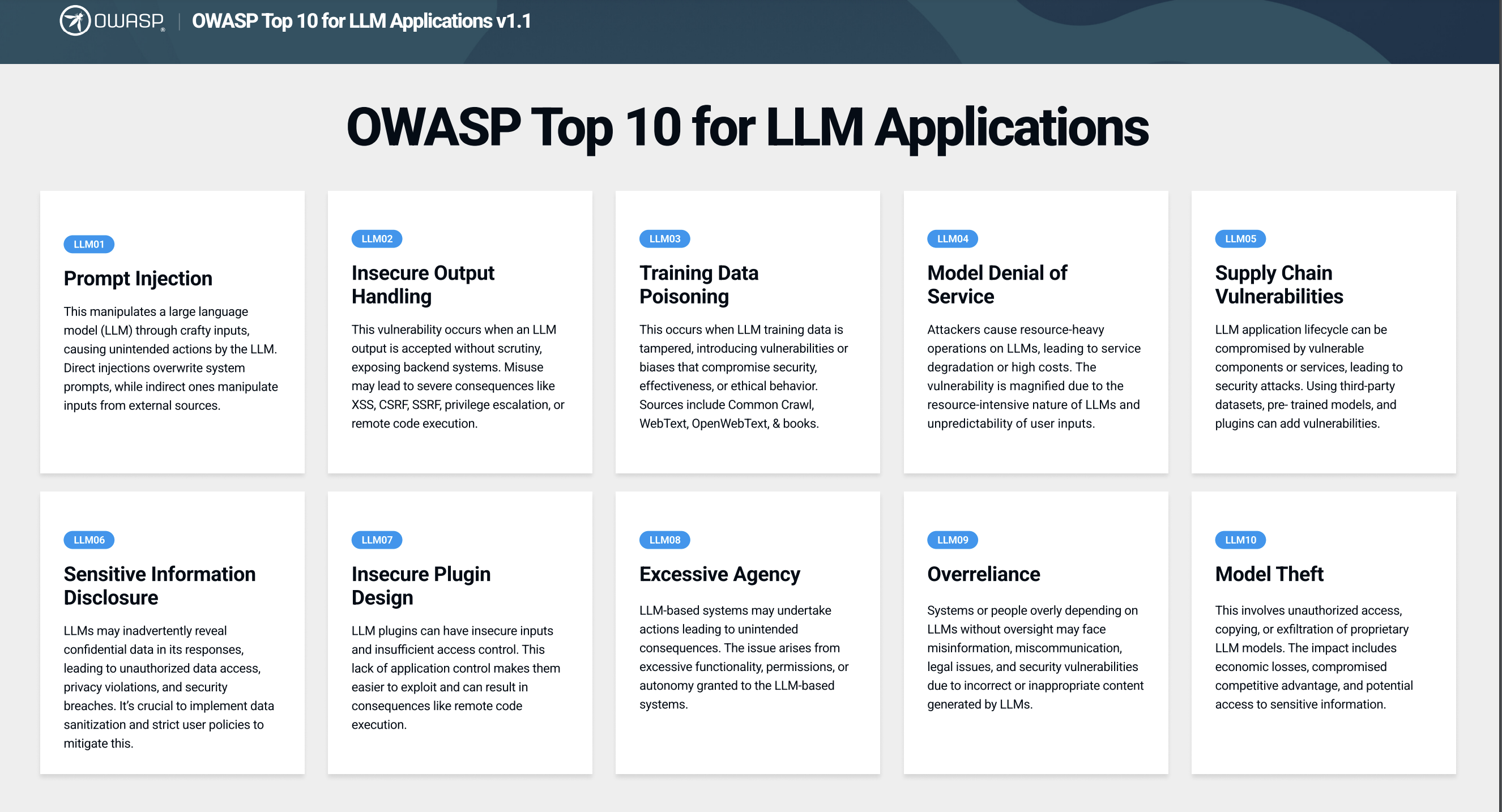
⛳️ OWASP 针对 LLM 应用 Top 10 潜在安全风险
2023.10.16发布 v1.1 版本
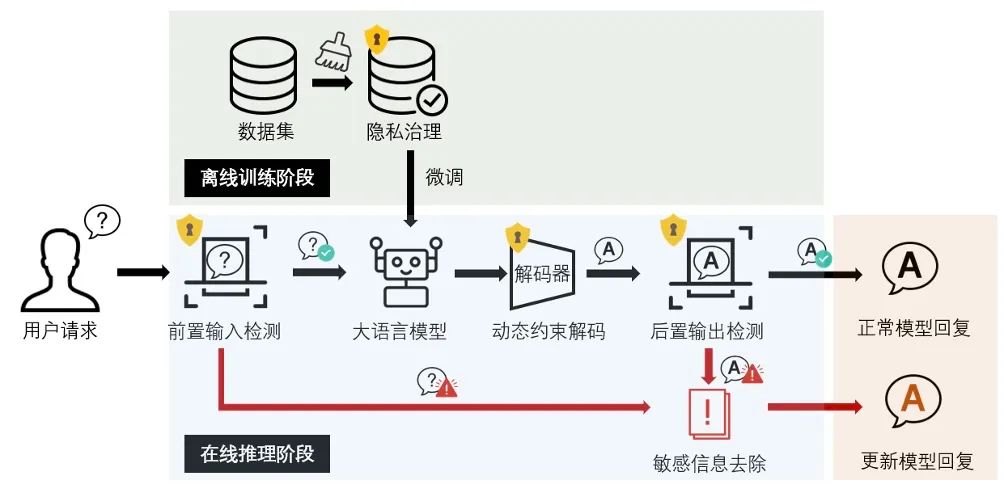
防止数据泄露的隐私保护策略
PII 保护
Personally Identifiable Information
包含:Credit Cards,Person Name,PHONE_NUMBER, URL,E-mail Addresses, IPs, UUID,US Social Security Number (SSN), Crypto wallet number(加密钱包号码), IBAN Code(国际银行账号)…
常规识别方法
- 基于规则(字符串匹配)
- 小的语言模型做实体识别,比如 bert-base-NER,bert-large-NER
整套的匿名处理方法(多策略组合)
- Microsoft 数据隐私保护SDK Presidio的隐私实体匿名化技术,相对MPC更高效的匿名化脱敏方案,但是无法在LLM生成的结果中还原被替换的隐私敏感信息
- LLM-guard方案更细化:整合了Presidio,提供 Anonymize scanner, Ban Substrings scanner,Ban Topics scanner …
- HaS(训练了一个权重文件仅500MB的小模型HaS-820m,用户无干预下的自动化脱敏和还原,以端到端的方式隐藏了命名实体识别、指代消解、文本生成等中间步骤):
-
步骤
- 平行替换隐私实体以实现隐私敏感信息的脱敏
- 还原云端LLM输出中的隐私实体以恢复可用性
-
做了一些 PII 数据标注工作;并进行黑盒和白盒攻击定量评估方案的隐私保护性能
-
虽然方法是从 prompt 角度来说明,但相关技术可直接用于对原始数据的处理(只需第一步平行替换)
-
LLM微调过程的隐私保护方式
常用微调技术
-
基本内容
-
底座模型(ChatGLM,LLaMA,BLOOM,Baichuan)
-
微调数据(主要是指令微调数据集)
基本结构:{“instruction”: { }, “input”: { }, “output”:{ }}
-
高效微调方案(Full-tuning, LoRA, Freeze, P-tuning)
- Full-tuning
- LoRA
- QLoRA: 量化后LLM的微调
- Freeze:参数冻结,对原始模型部分参数进行冻结操作,仅训练部分参数
- P-tuning
-
-
相关参考
-
微调思路总结:大模型微调项目 / 数据集调研汇总
-
基于ChatGLM-6B、ChatGLM2-6B模型,进行下游具体任务微调,涉及Freeze、Lora、P-tuning、全参微调等 (最新是23年8月更新):
https://github.com/liucongg/ChatGLM-Finetuning -
各类基座模型(LLaMA, BLOOM, Mistral, Baichuan, Qwen, ChatGLM)+ 微调策略(Full-parameter,Partial-parameter,LoRA,QLoRA):
https://github.com/hiyouga/LLaMA-Factory
-
隐私保护的模型微调
Offsite-Tuning: Transfer Learning without Full Model (场外微调)
Motivations:
-
传统上,用户将数据发送给模型所有者进行微调,这会引起隐私问题并产生高昂的计算成本(full parameter finetune)
-
模型所有者将完整模型发送给数据所有者是不切实际的,这会威胁到专有模型的所有权,而且由于资源限制,数据所有者无法承担对庞大基础模型进行微调的费用
-
场外微调为需要访问完整模型权重的传统微调方法提供了一种保护隐私的高效替代方法
Method:
全参数微调:需要访问完整的模型权重,并且需要模型和数据在一起。
场外微调:
- 模型方将适配器和模拟器发送给数据方
- 数据方在emulator 的帮助下对数据上的适配器进行微调;
- 将微调后的适配器返回并插入完整模型中,以创建经过调整的基础模型。
- 由于任何一方都不需要共享完整的模型或数据,并且emulator是压缩的,因此既保护隐私又高效。
缺点:很多选择和设计需要大量实验验证
- Adapter Selection:为了涵盖广泛的任务,适配器包含了模型的浅层和深层
- Emulator Compression:pruning, quantization, layer-drop, and knowledge distillation,验证发现layer-drop-based 压缩方法更合适
- 与 model 冻结部分相似
- 不能太精确,可能会泄露有关原始模型的信息
- 提供粗略的梯度方向来更新 Adapter 参数
优点:文本和视觉模型均做了验证
PrivateLoRA For Efficient Privacy Preserving LLM (蚂蚁金服, 2023.11.23)
Contributions:
- first efficient and privacy-preserving LLM solution
- 将隐私敏感计算分布在边缘设备上,并在云中分布共享计算
- 仅激活在中央云和边缘设备之间传输,确保数据存在本地
- 利用残差激活的低秩特性,实现超过 95% 的通信减少,同时提供与 LoRA 相当的调整性能
- 确认是否有隐私保护的分析【要有严谨的分析】
其他材料
LLM Safety 相关库
-
GPTSecurity:论文/工具的分类汇总,在更新中
-
llm-safety:每天在更新新文章
针对LLM-powered AI systems的攻击
The AI Attack Surface Map v1.0:Natural language is the primary means of attack for LLM-powered AI systems, and that it can be used to attack components of AI-powered systems throughout the stack. (结合Langchain的构件来说明)
安全相关的团队
JADE DB v2.0来袭—复旦白泽智能发布大模型安全通用测试集: 大模型安全测试相关【开源中文数据】
联邦LLM微调实现代码
ChatGLM 的联邦微调,支持LoRA 和 P-tuning V2的微调方法